みなさんこんにちは。
前回まででWebスクレイピング超初級は終了ですが、ただ情報を取るだけではつまらないので何か生活を便利にしたいなと考えをめぐらせておりました。
私は某アイドルグループのファンで彼女たちの出演情報は漏れなくチェックしているつもりなのですが、たまーに見逃すことがあり、悲しい思いをしたことがあります。ですので、テレビの出演情報をPythonにチェックさせてLINEに通知するプログラムを作りました。
Yahoo!テレビ.Gガイド [テレビ番組表]でキーワード検索していただくとわかるのですが検索後のURLには法則があることに気づきます。例えば「ニュース」というキーワードで、地域設定を東京、地上波&BS放送&CS放送、にすると以下のようになります。
https://tv.yahoo.co.jp/search/?q=ニュース&t=1%202%203&a=23&oa=1&s=1
私のサイトではないので法則に関して深堀することはやめておきますが、q=のあとがキーワード、a=のあとが地域設定、s=のあとがページ番号のはずです。のちほどソースコードを掲載しますが皆さんのやりたいことに応じてカスタムしてください。(地域設定に関してはURLのソースに記載がありました)動的なURLであればブラウザを自動で動かすようなプログラムが必要ですが今回はある程度単純なのでこれまで勉強した知識だけで処理ができそうです。
こんな感じのフローチャートでいきます。(見にくくてスミマセン)

今回はHTTPリクエストが正常かどうかのチェックを追加しています。こちらを参考にさせていただきました。

リクエストが正常でなければLINE Notifyを利用して通知します。
他は、検索数がゼロかどうかの判定、検索数からページ数を判断してループ処理、などを追加しています。
またURLのソースからあるタグの情報をゲットするにはChromeが大変便利です。ChromeでWebサイトを開いてから右クリック→「検証」を選ぶと、以下の画面が開きます。アイコンをクリックしてマウスを動かすと要素ごとのタグが自動で表示されていきます。こりゃ便利!
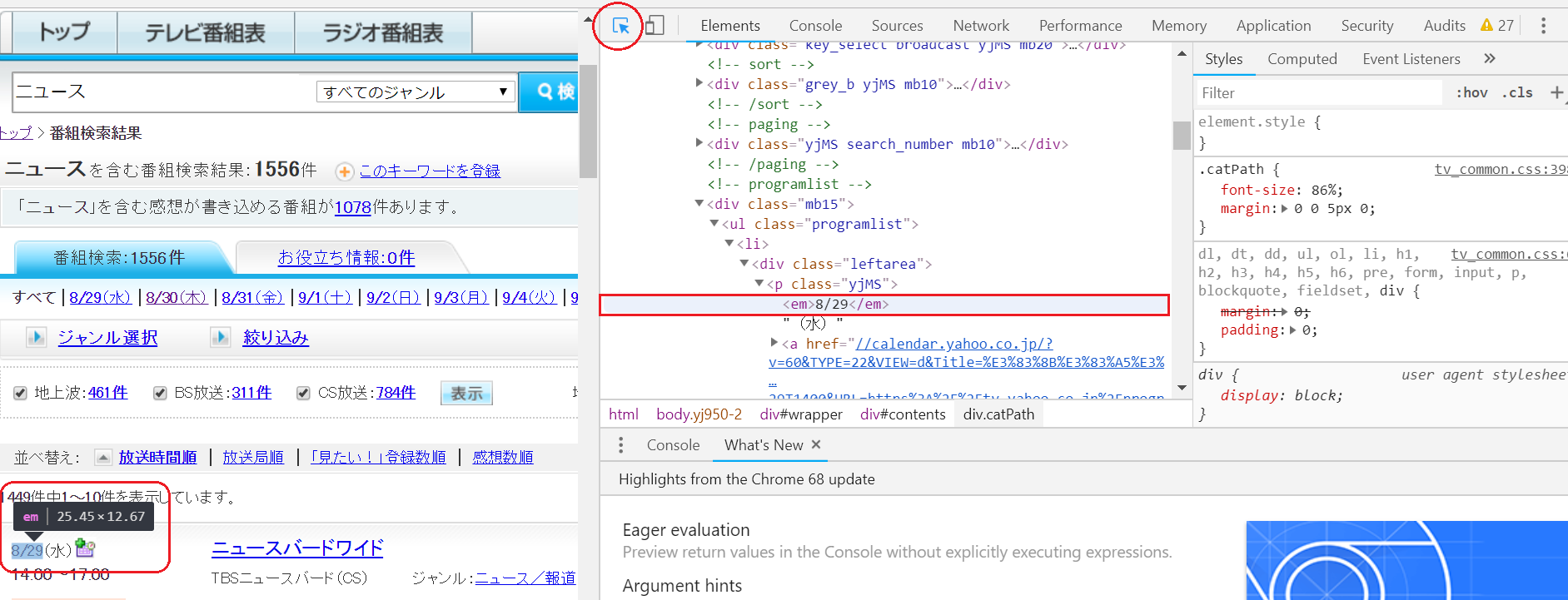
ではさっそくソースコードを記載します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
import requests from bs4 import BeautifulSoup import sys from time import sleep query = "ももいろクローバーZ" url = "https://tv.yahoo.co.jp/search/?q="+query+"&t=1%202%203&a=23&oa=1&s=1" #地上波、BS、CS 地域設定:東京 res = requests.get(url) status = res.status_code #Requestsのステータスコードが200以外ならばLINEに通知して終了 if status != 200: def LineNotify(message): line_notify_token = "アクセストークン" line_notify_api = "https://notify-api.line.me/api/notify" payload = {"message": message} headers = {"Authorization": "Bearer " + line_notify_token} requests.post(line_notify_api, data=payload, headers=headers) message = "Requestsに失敗しました" LineNotify(message) sys.exit() #ステータスコードが200ならば処理継続 else: pass #キーワード検索数を取得 soup = BeautifulSoup(res.text,"html.parser") p = soup.find("p",class_="floatl pt5p") #検索数が0ならば処理終了 if p == None: sys.exit() #以降の処理には進まず終了 #検索数が1以上ならば処理継続 else: pass answer = int(p.em.text) #検索数 page = 1 list1 = [] #放送日時用リスト list2 = [] #放送局用リスト list3 = [] #番組タイトル用リスト #検索数からページごとに情報取得を繰り返す処理 while answer > 0: url = "https://tv.yahoo.co.jp/search/?q="+query+"&t=1%202%203&a=23&oa=1&s="+str(page) #地上波、BS、CS 地域設定:東京 res = requests.get(url) soup = BeautifulSoup(res.text, "html.parser") dates = soup.find_all("div",class_="leftarea") for date in dates: d = date.text d = ''.join(d.splitlines()) list1.append(d) for s in soup("span",class_="floatl"): s.decompose() tvs = soup.find_all("span",class_="pr35") for tv in tvs: list2.append(tv.text) titles = soup.find_all("div",class_="rightarea") for title in titles: t = title.a.text list3.append(t) page = page + 10 answer = answer - 10 sleep(3) #list1~list3から放送日時+放送局+番組タイトルをまとめたlist_newの作成 list_new = [x +" "+ y for (x , y) in zip(list1,list2)] list_new = [x +" "+ y for (x , y) in zip(list_new,list3)] #テキストファイルから前回のデータを集合として展開する f = open('hogehoge.txt','r') #ファイル読み込み f_old = f.read() list_old = f_old.splitlines() #文字列を改行ごとにリスト化 set_old = set(list_old) #リストを集合に変換 f.close() # ファイルを閉じる #前回のデータと今回のデータの差集合をとる set_new = set(list_new) set_dif = set_new - set_old #差集合がなければ処理終了 if len(set_dif) == 0: sys.exit() #以降の処理には進まず終了 #差集合があればリストとして取り出してLINEに通知する else: list_now = list(set_dif) list_now.sort() for L in list_now: def LineNotify(message): line_notify_token = "アクセストークン" line_notify_api = "https://notify-api.line.me/api/notify" payload = {"message": message} headers = {"Authorization": "Bearer " + line_notify_token} requests.post(line_notify_api, data=payload, headers=headers) message = "新しい番組情報です\n\n" + L LineNotify(message) sleep(3) f = open('hogehoge.txt', 'w') # 書き込みモードで開く for x in list_new: f.write(str(x)+"\n") #list_newを文字列に変換&改行してファイル書き込み f.close() # ファイルを閉じる |
queryには皆さんが検索したいキーワード、URLは皆さんの状況に合わせてカスタムしてください。ブラウザで検索条件を変更したらURLも変わるはずです。
|
6 7 |
query = "ももいろクローバーZ" url = "https://tv.yahoo.co.jp/search/?q="+query+"&t=1%202%203&a=23&oa=1&s=1" #地上波、BS、CS 地域設定:東京 |
9~21行の部分、HTTPリクエストのステータスコードが200以外であればLINEに通知して処理を終了します。LINEの処理部分にあるアクセストークンはご自分の環境で取得したものを張り付けてください。
次にキーワード検索数を取得します。もし検索数がゼロであれば、29行のpには0でなくNoneが入ります。
|
27 28 29 30 31 32 33 34 35 36 37 |
#キーワード検索数を取得 soup = BeautifulSoup(res.text,"html.parser") p = soup.find("p",class_="floatl pt5p") #検索数が0ならば処理終了 if p == None: sys.exit() #以降の処理には進まず終了 #検索数が1以上ならば処理継続 else: pass |
ここから少しややこしいです。
検索数が1~10件ならばページ数は1、11~20件ならばページ数は2、というように増えていきます。検索数を取得してanswerに代入し、カウンタとして使用します。ループの最後でanswerから10を引いています。例えば検索数が30件ならば、
1回目の処理はanswer=30で1ページ目を取得
2回目の処理はanswer=20で2ページ目を取得
3回目の処理はanswer=10で3ページ目を取得
4回目の処理はanswer=0でループから抜ける
となります。スクレイピングするURLですが
|
47 |
url = "https://tv.yahoo.co.jp/search/?q="+query+"&t=1%202%203&a=23&oa=1&s="+str(page) #地上波、BS、CS 地域設定:東京 |
URLは最後の部分、s=”+str(page)としています。1ページ目はs=1ですが、2ページ目はs=2ではなく、s=11が正解で、3ページ目はs=21、というように増えていくので、ループの最後に変数pageに10を足しています。またループの最後でsleepを入れることでサーバへの負荷を軽減しています。
ループを抜けたあとは74、75行で取得した情報をまとめたリストを作成、77行以降は前回からお得意の差集合を使います。92行以降はLINEへの通知部分ですが、差集合で得られた「新しい番組情報」のデータをリストに変換しただけでは順番がバラバラなので.sort()で文字列順で並べ直しています。またLINE Notifyの通知もfor文で繰り返していますが、これはLINEに一度で送ることができる文字列に制限があるため、あえて1番組ずつ送るようにしました。最後に今回のデータをテキストファイルに保存して終了です。pyファイルと同じフォルダにhogehoge.txtがないとエラーになりますので注意してくださいね。
- ルーターの不調などでインターネットにつながらない場合が気づけない
- ループ内の処理で、放送日時、放送局、番組タイトルを別々に取得していくので、どこか一部の情報が欠けると全ての番組において正しくない情報となる恐れがある
- 番組タイトルが少し変更になっただけで、前回のデータと異なると判別されて通知されてしまう(本当は放送日時+放送局だけで判別すべきかもしれない)
など、少し問題点はありますが・・・
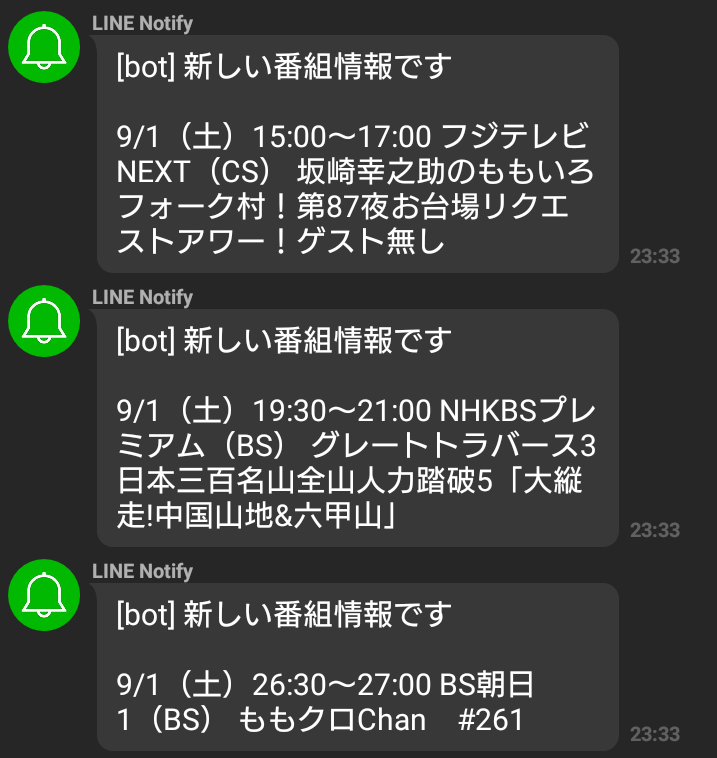
前回の投稿でLINE Notifyはグループでも使用できるということを記載しました。自分自身とLINE Notifyの2人だけでもグループを作ることができるので、処理ごとにグループを作れば情報が整理できてとても便利です。このAPI、ずっと使えるといいなぁ。
ひとまずこれで完成としたいと思います。お疲れ様でした。今回のプログラムを定期的に自動実行すれば素晴らしいオタクライフが待っているはずです。
さて次は何をやろうかな~。